JavaScript-rendered websites
If you want to scrape a dynamic website, chances are it is rendered using JavaScript and you cant simply access it using requests and beautifulsoup packages (Read more here to understand why). Selenium is one of the packages that’s very popular for this purpose.
Selenium
Using Selenium, you can write script to automate interaction with websites such as logging in, clicking buttons, scrolling, zooming etc. You would also need to download a special kind of browser called headless browser that can be controlled by Selenium. Chrome, Firefox all have their version of headless browser. This website has some good information and link to Chrome headless browser to get you started.
Assuming you have some knowledge about web-scraping, you’d want to use the inspect tool (in Chrome) to view the source code of the elements you want to extract. Selenium’s website is the best source on how to locate the elements once you’ve identified them.
Tip: in Chrome, you can right click the element you want to extract, then copy XPath to get the XPath of the element.
Scraping Datacamp
“Oh I remember there was this code to do this thing but I cant remember where it is”
I like the classes on Datacamp but it’s hard to look up something for reference. There is no search function for the lessons, you cant download the example texts and you have to click a few times to get to the class slides which is a pdf file. So I decided to scrape Datacamp to download all the pdf files for better and faster reference.
Scraping Datacamp is very straightforward. You log in, go to your track page, get a list of all the module links, then go through each module link to get a list of all classes, then go through each classes to get the texts and the pdfs you want. The trickiest part is figuring out where the elements you want to extract are.
The code
Full code on Github.
from selenium import webdriver
import requests
import os
# get working directory to save files
working_dir = os.getcwd()
# use special browser that Python can control
driver = webdriver.Chrome() #replace with .Firefox(), or with the browser of your choice
# open website to log in
# url_module = 'https://www.datacamp.com/tracks/data-scientist-with-python'
url_login = 'https://www.datacamp.com/users/sign_in'
driver.get(url_login)
# log in
username = driver.find_element_by_id("user_email") #username form field
password = driver.find_element_by_id("user_password") #password form field
username.send_keys("yourmail@somemail.com")
password.send_keys("password")
submitButton = driver.find_element_by_name("commit")
submitButton.click()
# get list of modules in Data Science track
modules = driver.find_elements_by_class_name('dc-activity-block__stat-dropdown-link')
Here, modules is a list of Selenium elements which have the same ‘dc-activity-block__stat-dropdown-link’ class. You have to access the href tag using get_attribute method in order to get the string of the link inside the element. The link is shortened to a relative path here but you will still get a full path.
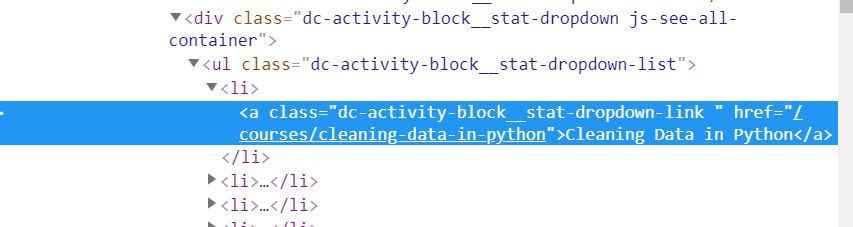
Similarly for the pdf file, the link is stored in the data attribute.

# extract links from web elements
module_list = [i.get_attribute('href') for i in modules]
# Remove empty modules
module_list = [module for module in module_list if module!=None]
# len(module_list)
# 24
# loop to go through each module
for module in module_list:
# create folder for text files and pdfs
module_name = module.split(sep='/')[-1] # get name of the module by spliting the http link and get the last string
new_dir = os.path.join(working_dir, module_name)
if not os.path.exists(new_dir):
os.makedirs(new_dir)
# go to the module's website and find all classes/lessons
driver.get(module)
# find all classes/lessons
lessons = driver.find_elements_by_class_name('chapter__exercise-link')
lesson_list = [i.get_attribute('href') for i in lessons]
# lesson_name_list = []
# loop to go through each class/lesson page until all texts and pdf files are found
for lesson in lesson_list:
try:
# url = classes_list[i]
driver.get(lesson) # navigate to the page
# doesnt seem to have login/password protected
# find all lesson texts
lesson_text = driver.find_element_by_id('rendered-view').text
# only get the visible code, need to scroll or change window size to get all codes
# code = driver.find_element_by_xpath('//*[@id="ace-code-editor-6"]').text
# get lesson name by splitting into a list using '/' then choose the last item
lesson_name = lesson.split(sep='/')[-1]
lesson_name = lesson_name.replace('?', '_') + '.txt'
# lesson_name_list.append(lesson_name)
# save text to file .txt
text_link = os.path.join(working_dir, module_name, lesson_name)
if not os.path.isfile(text_link):
with open(text_link, 'w') as f:
f.write(lesson_text)
# find pdf files in the lesson page
pdf = driver.find_element_by_xpath('//*[@id="gl-consoleTabs-slides"]/div/div/object').get_attribute('data')
pdf_name = pdf.split(sep='/')[-1]
pdf_link = os.path.join(working_dir, module_name, pdf_name)
if not os.path.exists(pdf_link):
# download pdf files
r = requests.get(pdf)
with open(pdf_link, 'wb') as f:
f.write(r.content)
# video pages wont have the elements we're looking for so continue to the next item; multiple-choice pages also dont have pdf link
except:
continue
It took about half an hour to crawl through all 22 modules, each module has about 50 small lessons. Definitely better than me clicking each lesson and manually saving each pdf file.